Welcome to the world of data! With the rise of technology and digitalization, the amount of data being generated every day is increasing exponentially. This has led to the development of various techniques and algorithms to analyze and make sense of this vast amount of data. Three of the most popular and in-demand technologies in this field are machine learning, data science, and deep learning. In this comprehensive guide, we will dive deep into these three areas and understand how they work together using the powerful language of Python.
Introduction to Machine Learning
Machine learning is a subset of artificial intelligence (AI) that enables systems to learn and improve from experience without being explicitly programmed. It involves training models on large datasets to make predictions or decisions based on new data. These models are trained using different algorithms that allow them to identify patterns and relationships in the data and make accurate predictions.
History of Machine Learning
The concept of machine learning can be traced back to as early as 1950 when Alan Turing proposed the “Turing Test” to determine if a computer can think like a human being. But it wasn’t until the 1980s when machine learning truly started to take shape with the development of neural networks and decision tree algorithms. In the 1990s, with the advent of the internet and the availability of large datasets, machine learning gained even more popularity.
In recent years, advances in computing power, along with the availability of open-source tools and libraries, have made machine learning accessible to a wider audience. Today, machine learning is used in various industries, including finance, healthcare, marketing, and many others.
Types of Machine Learning
There are three main types of machine learning: supervised learning, unsupervised learning, and reinforcement learning.
Supervised Learning
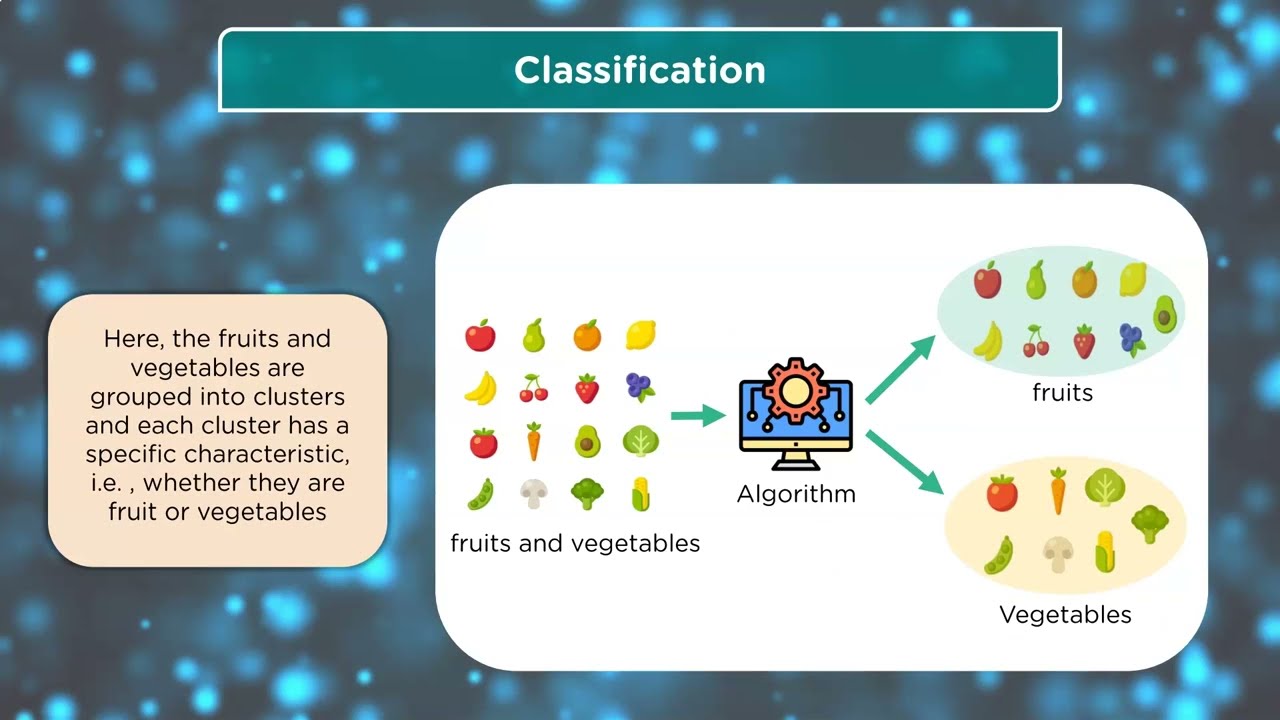
Supervised learning involves training a model on a labeled dataset, where the input features and the desired output are known. The aim of supervised learning is to map the input features to the desired output and make accurate predictions on new data. Some common algorithms used in supervised learning include linear regression, logistic regression, decision trees, and support vector machines.
Unsupervised Learning
In unsupervised learning, the model is trained on an unlabeled dataset, where the input features are given, but the desired output is unknown. The goal of unsupervised learning is to identify patterns and relationships in the data without any prior knowledge or labels. Clustering, dimensionality reduction, and anomaly detection are some of the techniques used in unsupervised learning.
Reinforcement Learning
Reinforcement learning involves training a model to make decisions based on its environment. The model learns from feedback in the form of rewards or penalties and improves its performance over time. This type of learning is commonly used in robotics, gaming, and autonomous vehicles.
Introduction to Data Science

Data science is an interdisciplinary field that combines techniques from mathematics, statistics, computer science, and domain expertise to extract insights and knowledge from data. It involves collecting, organizing, analyzing, and interpreting large datasets to solve complex problems and make data-driven decisions.
History of Data Science
The term “data science” was first coined by William S. Cleveland in 2001, but the idea of using data to solve problems has been around for centuries. From Florence Nightingale’s statistical analysis of mortality rates during the Crimean War to the use of data to predict weather patterns, the concept of data science has evolved with the advancement of technology.
With the rise of big data in the early 2000s, data science gained even more traction. Today, data scientists are in high demand in various industries as companies strive to stay ahead of their competition by leveraging the power of data.
Skills Required for Data Science
Data science is a multidisciplinary field that requires a combination of technical and non-technical skills. Some of the essential skills for a data scientist include:
- Programming: Proficiency in programming languages like Python, R, or SQL is crucial for data scientists as they need to work with large datasets and build models.
- Statistics and Mathematics: A strong understanding of statistics and mathematics is necessary to analyze data and build predictive models.
- Machine Learning: Knowledge of machine learning algorithms and techniques is essential for data scientists to make accurate predictions on new data.
- Data Wrangling and Visualization: Data scientists must be able to clean and transform messy data into a format suitable for analysis and communicate insights through visualizations.
- Domain Expertise: Having domain expertise in a particular field, such as finance, healthcare, or marketing, can give data scientists an edge when working on specific projects.
Steps Involved in a Data Science Project
A typical data science project involves the following steps:
- Problem Statement: The first step in any data science project is to define the problem you want to solve. This could be anything from identifying patterns in customer behavior to predicting stock market trends.
- Data Collection: Data scientists gather data from various sources, such as databases, APIs, web scraping, or surveys. This data can be structured, unstructured, or semi-structured.
- Data Cleaning and Preprocessing: Data cleaning involves removing irrelevant or incorrect data, dealing with missing values, and handling outliers. Preprocessing involves transforming the data into a format suitable for analysis.
- Exploratory Data Analysis (EDA): EDA is an essential step where data scientists explore and visualize the data to understand its characteristics and identify any patterns or relationships.
- Feature Engineering: Feature engineering involves creating new features from existing ones to improve model performance.
- Model Building: Data scientists select and train the best machine learning algorithm based on the problem at hand and the type of data available.
- Model Evaluation: The performance of the model is evaluated using different metrics to determine how well it can make predictions.
- Model Deployment: Once the model is trained and evaluated, it is deployed into production for real-world use.
- Monitoring and Maintenance: Data scientists continuously monitor the model’s performance and make necessary changes to ensure its accuracy and effectiveness.
Introduction to Deep Learning
Deep learning is a subset of machine learning that uses artificial neural networks (ANNs) to learn from data. It involves training deep neural networks with multiple hidden layers to extract features from raw data and make accurate predictions. Deep learning has gained popularity in recent years due to its ability to handle complex and unstructured data, such as images, audio, and text.
History of Deep Learning
The concept of artificial neural networks dates back to 1943 when Warren McCulloch and Walter Pitts proposed a mathematical model of how neurons work. In the 1980s, the development of the backpropagation algorithm enabled training of deep neural networks with multiple layers. However, deep learning only gained mainstream attention when Alex Krizhevsky used deep convolutional neural networks to win the ImageNet competition in 2012.
Today, deep learning is used in various applications, including image recognition, natural language processing, speech recognition, and many others.
Basics of Artificial Neural Networks
Artificial Neural Networks (ANNs) are computational models inspired by the structure and functioning of the human brain. They are composed of interconnected nodes or “neurons” arranged in layers. Each node takes in input signals, processes them, and produces an output signal. These signals are then passed on to the next layer of neurons until the final output is generated.
Types of Layers in Artificial Neural Networks
- Input Layer: The input layer receives the raw data and passes it on to the hidden layers for processing.
- Hidden Layers: Hidden layers are sandwiched between the input and output layers and perform most of the computation in an ANN. They extract features from the input data and pass them on to the next layer.
- Output Layer: The output layer produces the final prediction or decision based on the inputs and the learned patterns.
Types of Artificial Neural Networks
- Feedforward Neural Networks: Feedforward neural networks are the most basic type of ANNs, where data flows in only one direction – from the input to the output layer.
- Recurrent Neural Networks (RNN): In RNNs, the output of a previous step is fed back as an input to the current step, allowing them to process sequential data.
- Convolutional Neural Networks (CNN): CNNs are specialized for processing images and use convolutional layers to filter and extract features from the input images.
- Generative Adversarial Networks (GAN): GANs involve two deep neural networks competing against each other – a generator network that creates new data samples and a discriminator network that learns to differentiate between real and fake data.
Basics of Python for Machine Learning
Python has become the go-to language for machine learning due to its simplicity, ease of use, and extensive libraries and tools for data science. Here are some essential concepts and libraries in Python that you need to know to get started with machine learning.
Variables and Data Types
Variables are used to store data values in computer programs. In Python, variables can be defined using the “=” operator. For example:
x = 5In this case, the variable x is assigned the value of 5. Python also supports different data types, such as strings, integers, floats, booleans, and others.
Control Flow Statements
Control flow statements are used to control the flow of execution in a program. Some common control flow statements in Python include if-else statements, while loops, and for loops.
if x > 10:
print("x is greater than 10")
else:
print("x is less than or equal to 10")In this example, the code inside the if block will be executed if the condition x > 10 is true, and if not, the code inside the else block will be executed.
NumPy
NumPy is a fundamental library for scientific computing in Python. It provides support for multi-dimensional arrays and matrices, along with a wide range of mathematical functions. NumPy arrays are highly efficient and can handle large datasets with ease.
import numpy as np
# Create a 2D array with random values
arr = np.random.rand(3, 3)Pandas
Pandas is a popular library for data manipulation and analysis in Python. It provides powerful tools for working with tabular data, such as importing and exporting data, cleaning and preprocessing, merging and joining data, and handling missing values.
import pandas as pd
# Import data from a CSV file
df = pd.read_csv('data.csv')
# View first 5 rows of the dataset
print(df.head())Matplotlib
Matplotlib is a widely-used library for creating visualizations in Python. It provides various functions and methods for creating different types of plots, including line charts, bar graphs, histograms, scatter plots, and many more.
import matplotlib.pyplot as plt
# Create a line plot using NumPy arrays
x = np.linspace(-2*np.pi, 2*np.pi, 100)
y = np.sin(x)
plt.plot(x, y)Data Preprocessing
Data preprocessing is a crucial step in any machine learning project. It involves cleaning and transforming the raw data into a format suitable for analysis and model training. Here are some common techniques used for data preprocessing:
Handling Missing Values
Missing values are a common occurrence in real-world datasets. There are several ways to handle missing values, such as:
- Deleting rows or columns: If the number of missing values is relatively small, you can choose to remove the rows or columns containing them.
- Imputation: In this method, the missing values are filled with a valid value. This could be the mean, median, or mode of the column or using advanced techniques like K-nearest neighbors (KNN) or regression.
- Creating a new category: For categorical features, missing values can be replaced with a new category, such as “unknown.”
Feature Scaling
Feature scaling is the process of scaling numeric features to a similar scale to improve model performance. Some common methods for feature scaling include standardization and normalization.
- Standardization: Standardization involves transforming the data into a standard normal distribution with a mean of 0 and standard deviation of 1. This can be achieved using the
StandardScalerfrom scikit-learn. - Normalization: Normalization scales the values between 0 and 1 and is useful when the dataset has outliers. The
MinMaxScalerfrom scikit-learn can be used for normalization.
Encoding Categorical Features
Machine learning algorithms can only work with numerical data, so categorical features need to be converted into numerical form before they can be used for training. Two popular methods for encoding categorical features are one-hot encoding and label encoding.
- One-Hot Encoding: One-hot encoding creates dummy variables for each category in a feature and replaces the original feature with these new binary features. For example, a feature with three categories would be converted into three binary features.
- Label Encoding: In label encoding, each category is assigned a numeric label starting from 0 to n-1, where n is the number of categories. This method is useful when the categories have some inherent order or rank.
Supervised Learning
Supervised learning involves training a model on a labeled dataset, where the input features and the desired output are known, and using this model to make predictions on new data. Here are some popular algorithms used in supervised learning:
Linear Regression
Linear regression is a simple yet powerful algorithm used for predicting continuous values. It works by finding the best-fitting line that minimizes the error between the predicted and actual values. The slope and intercept of this line are determined using the least-squares method.
Logistic Regression
Logistic regression is a classification algorithm used to predict binary outcomes (0 or 1). Unlike linear regression, which outputs continuous values, logistic regression outputs probabilities between 0 and 1. These probabilities can then be mapped to different classes based on a threshold value.
Decision Trees
Decision trees are popular supervised learning algorithms that work by splitting the data into smaller subsets based on certain criteria at each node. These nodes continue to split until a leaf node is reached, which contains the final decision or prediction. Decision trees are easy to interpret and visualize, making them useful for both classification and regression tasks.
Unsupervised Learning
Unsupervised learning involves training a model on an unlabeled dataset, where the input features are given, but the desired output is unknown. The goal of unsupervised learning is to discover patterns and relationships in the data without any prior knowledge or labels. Here are two popular techniques used in unsupervised learning:
Clustering
Clustering is a technique used to group similar data points together based on their characteristics. The aim is to maximize the similarity within a cluster and minimize the similarity between different clusters. Clustering is commonly used for market segmentation, customer profiling, anomaly detection, and many other applications.
Dimensionality Reduction
Dimensionality reduction involves reducing the number of input features while retaining the most important information. This is useful when working with high-dimensional datasets that make it difficult to visualize or analyze the data. Principal Component Analysis (PCA) and t-distributed Stochastic Neighbor Embedding (t-SNE) are popular methods for dimensionality reduction.
Deep Learning Algorithms
Deep learning algorithms have gained popularity in recent years due to their ability to handle complex and unstructured data, such as images, audio, and text. Here are some common deep learning architectures used in various applications:
Convolutional Neural Networks (CNN)
CNNs are deep neural networks designed specifically for image recognition. They use convolutional layers to extract features from images and pass them on to fully connected layers for prediction. CNNs have shown remarkable performance in tasks like image classification, object detection, and facial recognition.
Recurrent Neural Networks (RNN)
RNNs are specialized for processing sequential data such as text, speech, and time series data. They have a “memory” that allows them to remember previous inputs and use this information to predict future outputs. This makes RNNs suitable for applications like language translation, speech recognition, and stock market forecasting.
Generative Adversarial Networks (GAN)
GANs involve two deep neural networks competing against each other – a generator network that creates new data samples and a discriminator network that learns to differentiate between real and fake data. GANs have been used to generate realistic images, videos, and even music.
Machine Learning Projects
Now that we have covered the basics of machine learning, data science, and deep learning, let’s look at some interesting projects you can try to apply your knowledge.
House Price Prediction
This project involves building a machine learning model to predict the prices of houses based on different features like location, number of rooms, and area. You can use regression algorithms such as linear regression, decision trees, or XGBoost for this project.
Image Classification
In this project, you will build an image classifier to classify images of different objects or animals. You can use CNNs for this task and train the model on popular datasets like MNIST, CIFAR-10, or ImageNet.
Sentiment Analysis
Sentiment analysis involves analyzing text data to determine the writer’s attitude, emotions, or opinions towards a particular topic. You can use RNNs or transformers like BERT for this project and train the model on movie reviews, tweets, or product reviews dataset.
Advanced Topics in Machine Learning
After mastering the basics of machine learning, you can explore advanced topics to enhance your skills further. Some of these include:
- Natural Language Processing (NLP): NLP involves using machine learning techniques to analyze and understand human language. It has applications in sentiment analysis, speech recognition, language translation, and many others.
- Reinforcement Learning: Reinforcement learning involves training a model to make decisions based on rewards or penalties given by its environment. This type of learning is commonly used in robotics, gaming, and control systems.
- Transfer Learning: Transfer learning involves leveraging pre-trained models on large datasets to improve performance on new tasks with limited data. This technique is useful when you have a small dataset for a particular task but can benefit from the knowledge learned in a related task with a larger dataset.
Conclusion
In conclusion, machine learning is a powerful field that has revolutionized various industries by enabling computers to learn from data and make intelligent decisions. From data preprocessing to deep learning algorithms, we have covered the essential topics in this article to provide you with a solid foundation in machine learning.
By understanding the concepts of supervised and unsupervised learning, as well as deep learning algorithms like CNNs, RNNs, and GANs, you can start building predictive models, image classifiers, sentiment analysis tools, and much more.
As you continue your journey in machine learning, consider working on projects like house price prediction, image classification, and sentiment analysis to apply your knowledge in real-world scenarios. Additionally, exploring advanced topics such as NLP, reinforcement learning, and transfer learning will help you stay at the forefront of this rapidly evolving field.
Remember, continuous learning and practice are key to mastering machine learning. Keep experimenting with different algorithms, datasets, and techniques to hone your skills and become a proficient machine learning practitioner. With dedication and persistence, you can unlock endless possibilities in the world of artificial intelligence and make meaningful contributions to society. Good luck on your machine learning journey!